Roundup of Google updates from November 2020
November has been pretty busy in the parallel universe of the digital world with online business activity in full swing.

November was the second to last month of 2020 and part of the last quarter, which tends to be the least productive of every financial calendar. However, it’s been pretty busy in the parallel universe of the digital world with online business activity in full swing.
Throughout last month Google has been seamlessly spreading out the word and the search evangelists have been religiously implementing all these new things that make the users’ and publishers’ life easier and more effective.
From May 2021 the Web Core Vitals will be a ranking signal and the user’s page experience will be measured and scored for ranking purposes.
Amongst others, Google suggested that you keep pillar pages, such as Black Friday URLs, permanent to get the most out of its maturing link equity and rank better in the long run.
Through public discussions in the search community, we saw some controversial questions being asked and answered, giving us a better understanding of the algorithm’s rationale.
Do Google’s machine learning mechanisms need exact match keywords? Is Google actually doing something about expired domain schemes? Why should you check now if you are eligible for the brand-new HTTP/2?
Last but not least, the holy grail of webmasters once called Google Webmasters Central, changed its name to Google Search Central to better include and centralise its scope of interests.

2nd Nov: Google say permanent URLs for Black Friday pages
Google suggests that it’s better to use permanent URLs for Black Friday and Cyber Monday pages than to create new URLs every year.
So far, a common practice for many site owners is to set up a new page yearly for Black Friday sales but remove it after the period ends.
Why should you care all year round?
Google believes that temporary pages are not good practice. A permanent, recurring page will help the page to rank in the future.
Use a recurring URL, not a new URL for each occurrence of the event. Give the landing page of recurring events a meaningful URL that reflects the event that is used each year (for example use /sale/black-friday, not /sale/2020/black-friday).
Google
Why is that?
Link equity. Recurring URLs help sites to build link equity, a.k.a link juice, which is the SEO value built over time, or the value that is exchanged between sites that link to each other. The older the URL the more link equity is potentially built up and so more chances to rank in search results.
From our experience, this practice is not only good for Black Friday URLs but also in topics that you can help your business grow and educate your audience. For example, if specific sections of your site perform well and drive traffic, you should consider creating a separate permanent page where your content is being put. You can expect it to build link equity and authority and you can reap the fruits in the long run.

Google’s roadmap for Black Friday and Cyber Monday sales in search results:
- Publish early: The Googlebot needs time to crawl and index your Black Friday sales page.
- Follow standard SEO practices: follow reliable SEO experts for solid tips and practices. Please head to our Minttwist SEO for expert advice and give us a nudge in case you have any questions.
- Internal linking to the landing page: link the home page as well as other pages to the Black Friday page. This will signal to Google the urgency and importance of the page and will make it more readily available to visitors.
- Use high-quality, relevant images: showcase your Black Friday page sales with a static and up-to-date image. Trim any whitespace around the image and make sure it’s visually appealing.
- Make sure the landing page is recrawled: as soon as you have updated your, in this instance, Black Friday, landing page, ask Google to recrawl it so your content is updated quickly.
4th Nov: How Google chooses a canonical page
Another Google’s Search Off The Record podcast and Gary Illyes, member of Google’s search relations team, shares insights on how Google identifies canonical pages and duplicates.
In this episode, Gary Illyes shared enough information about the way Google detects duplicate pages and chooses the canonical page to be eligible for the search results.
He also advised that there are twenty different signals that are weighted in order to identify the canonical page and how machine learning is used to adjust the weights.
So how does Google deals with canonicalisation?
We collect signals and now we ended up with the next step, which is actually canonicalisation and dupe detection.
Gary Illyes, Webmaster trends analyst at Google
…first, you have to detect the dupes, basically cluster them together, saying that all of these pages are dupes of each other. And then you have to basically find a leader page for all of them.
And how we do that is perhaps how most people, other search engines do it, which is basically reducing the content into a hash or checksum and then comparing the checksums
…and so we are reducing the content into a checksum and we do that because we don’t want to scan the whole text because it just doesn’t make sense. Essentially it takes more resources and the result would be pretty much the same. So we calculate multiple kinds of checksums about textual content of the page and then we compare to checksums.
Is this process catching near-duplicates or exact duplicates?
It can catch both. It can also catch near duplicates.
We have several algorithms that, for example, try to detect and then remove the boilerplate from the pages.
So, for example, we exclude the navigation from the checksum calculation. We remove the footer as well. And then you are left with what we call the centerpiece, which is the central content of the page, kind of like the meat of the page.”
What is a checksum?
A checksum is basically a hash of the content. Basically a fingerprint. Basically, it’s a fingerprint of something. In this case, it’s the content of the file…
Gary Illyes, Webmaster trends analyst at Google
And then, once we’ve calculated these checksums, then we have the dupe cluster. Then we have to select one document, that we want to show in the search results.
Why Google prevents duplicate pages from appearing in the SERP?
We do that because typically users don’t like it when the same content is repeated across many search results. And we do that also because our storage space in the index is not infinite.
Gary Illyes, Webmaster trends analyst at Google
Basically, why would we want to store duplicates in our index?
Detecting duplicates and selecting the canonical page:
But, calculating which one to be canonical, which page to lead the cluster, is actually not that easy. Because there are scenarios where even for humans it would be quite hard to tell which page should be the one that to be in the search results.
Gary Illyes, Webmaster trends analyst at Google
So we employ, I think, over twenty signals, we use over twenty signals, to decide which page to pick as canonical from a dupe cluster. But it could be also stuff like PageRank for example, like which page has higher PageRank, because we still use PageRank after all these years.
It could be, especially on the same site, which page is on an HTTPS URL, which page is included in the sitemap, or if one page is redirecting to the other page, then that’s a very clear signal that the other page should become canonical, the rel=canonical attribute… is quite a strong signal again because someone specified that other page should be canonical.
And then once we compared all these signals for all page pairs then we end up with actual canonical. Each of these signals that we use have their own weight. We use some machine learning voodoo to calculate the weights for these signals.
Gary went on sharing personal stories from his attempts to manually introduce new ways of adjusting the weights concluding that weighting signals are interrelated and one needs machine learning implementation to stand any chances of successfully making any changes to the weighting.
10th Nov: Google on crawl rate for big and small sites
Google’s John Mueller answers tweets on whether big sites come with a crawl rate advantage over smaller sites in terms of the URL submission tool.
When John wondered how come people are missing the URL submission tool, a Twitter user claimed that because larger sites are crawled more often, small sites are disadvantaged.
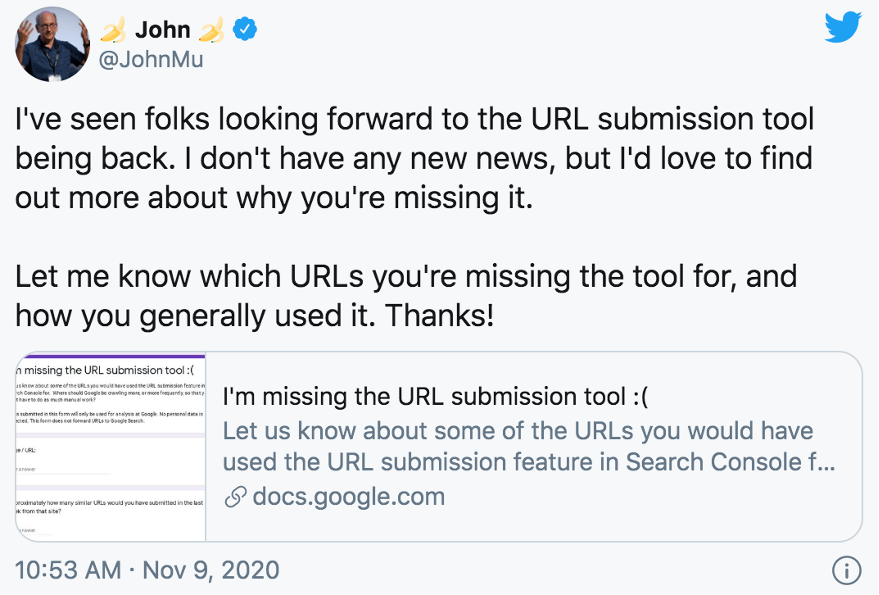
This statement sparked a discussion that helped us extract some interesting insights.
Crawling is independent of website size. Some sites have a gazillion (useless) URLs and luckily we don’t crawl much from them. If you have an example from your site where you’re seeing issues feel free to add it to the form.
John Muller via Twitter
The person replied that some publishing platforms that certain publishing sites do not update their sitemaps automatically.
John Mueller suggested that the simpler approach is to upgrade the platform so that it automatically updates the sitemap.
There are still sites that don’t use sitemaps? Seems like a much simpler fix than to manually submit every new or updated URL. Manual submissions are never scalable, make sure it works automatically. Making a sitemap file automatically seems like a minimal baseline for any serious website.
John Mueller via Twitter
10th Nov: Core Web Vitals ranking signal in May 2021
Google announces that the Core Web Vitals will become ranking signals as of May 2021.
What are the Core Web Vitals?
Core Web Vitals are a set of specific variables that Google factors in to score the user experience of a webpage. From May 2021, the Core Web Vitals and other already existing “page experience” signals will be combined to measure the UX score of a webpage.
Core Web Vitals:
- Largest Contentful Paint: The time a page’s main content needs to load. Ideal LCP time: 2.5 seconds or faster.
- First Input Delay: The time page needs to become interactive. Ideal FID time: less than 100 ms.
- Cumulative Layout Shift: The unexpected layout shift of visual page content known as “visual stability”. Ideal measurement: less than 0.1.
The Core Web Vitals change every year as user expectations of web pages change as well.
UX-related Signals:
- HTTPS
- Mobile-friendliness
- Safe Browsing
- Interstitial pop-ups
Interestingly enough, Google will add labels in search results that will indicate which results provide a good page experience. Google is working towards creating visual indicators to identify pages that meet all page criteria. It seems that a lot of work is to be done as a recent study from Screaming Frog showed that less than 15% of sites are passing the Core Web Vitals assessment.
Indeed, webmasters have been seamlessly working to make their pages’ user experience signal friendly. Google has reported that there’s been a 70% increase in sites that have sought advice from Google’s Core Web Vitals tools for page experience improvement.
Google’s new announcement came with the news that non-AMP pages will be eligible to show in the top stories carousel also from May 2021 onwards. AMP content will be still supported and considered in search results the same way as always.
10th Nov: Google’s John Mueller on BERT and exact match keywords
Does BERT impact the need for exact match keywords on web pages?
That was one of the questions that Mueller was called to answer in that day’s Google SEO office-hours hangout.
But before we walk through the hangout’s interesting chat.
What BERT stands for? Bidirectional Encoder Representations from Transformers.
In plain words, Google has found ways to develop more sophisticated transformers, essentially neural-based models for natural language processing. So, what’s the deal?
These models are intelligent to the point that can understand what you mean when you make a search query. The full context around your typed word by looking at the broader content, not just the meaning of the word itself. In other words, Google can be highly accurate in understanding what your actual search intent is.
Question:
“With BERT coming out, will the importance of the exact keyword, exact match keyword decrease?”
John Mueller responded:
From my point of view, all of these changes that have been happening over the years, they do lead in the direction that you don’t have to have the exact keywords on your pages anymore.
John Mueller, Senior webmaster trends analyst at Google
And this is something that I think SEOs have seen kind of maybe subconsciously over the years as well, where they realize oh you don’t need to have singular and plural versions on your page. You don’t need to have all of the common misspellings on your page. All of those things are less critical on your pages as long as you really match what the user is actually looking for.
Mueller went on clarifying that the purpose of BERT and other algorithms is not to make exact match keywords less important but rather to extract the most useful answers to the search queries.
The exact match keywords topic is traditionally a quite crucial one for the design of content strategies. As exact keywords are being targeted to match specific URLs building authority and driving traffic.
Bottom line is that good practice is to keep on writing content that answers what the query is after. If you need a specific keyword to achieve that it should be fine.

10th Nov: what Google does to tackle expired domain schemes?
In the same episode of Google SEO office-hours hangout, Mueller was asked whether Google does anything to stop people from using expired domains in a sneaky way.
The longstanding topic of expired domains is referring to the practice of using (oftentimes buying) an expired domain in order to take leverage of the existing backlinks and build a new site that ranks or redirect the expired domain to another domain they are aiming to rank for.
Question:
“I see many discussions about people buying expired domains to take advantage of links associated with the expired domains.
“What they do is build a site on an expired domain or they redirect an expired domain to a second domain that they want to rank.
“Does Google reset the backlinks of expired domains so that they don’t have an effect when someone buys them and builds a site on the expired domain?”
Mueller said that even though Google always attempts to detect expired domains and the way they are used, it is sometimes difficult to understand suspicious use as sometimes domains are used in a perfectly innocent and legitimate way.
John Mueller responded:
Our systems try to understand what to do here and for the most part, I think we get this right. So it’s not that there’s any one specific factor that we would look at and say, oh they’re trying to do something sneaky with those expired domains.
John Mueller, Senior webmaster trends analyst at Google
We need to be super cautious. Sometimes people revive expired domains and they really kind of run the old website again. Sometimes people sometimes pass on a website from one owner to another, so… domain name changes ownership. And those are all normal situations and it’s not the case that Google should go in there and say oh… we need to be extra cautious here.
Mueller went on explaining that caution is key in handling expired domains. He pointed out that numerous domains have been registered and then dropped in the past, and this makes it almost impossible to identify domains that haven’t been registered in the past.
Our key takeaway from this discussion is that Mueller never actually answered if the expired domain links are reset or not. Resetting the link of a domain means to strip the domain from the links, essentially all the work the previous webmaster did to build backlinks for ranking purposes.
11th Nov: Google announced webmasters’ new brand name: Google Search Central
Google Webmasters Central changes its name to Google Search Central and introduces an updated version of its mascot featuring the infamous Googlebot.
The blog introduced us to the news, by giving us the historical background of the term webmaster, which is part of the brand name, and its use seems to be in a constant decline.
Merriam-Webster claims the first known use of the word “webmaster” was in 1993, years before Google even existed. However, the term is becoming archaic, and according to the data found in books, its use is in sharp decline. A user experience study we ran revealed that very few web professionals identify themselves as webmasters anymore. They’re more likely to call themselves Search Engine Optimizer (SEO), online marketer, blogger, web developer, or site owner, but very few “webmasters”.
Google
Google had to figure out the most inclusive term that best describes the work people do on websites. As the blog constitutes a common denominator of the SEO community and the site owners from a search standpoint, it rebranded itself to “Google Search Central” both on websites and social media.
Our goal is still the same; we aim to help people improve the visibility of their website on Google Search.
Google
Google also confidently announced the consolidation of its blogs and help documentation by centralising to one site.
The Search Central site is now coming with all help documentation, crawling, indexing, search guidelines, and all search-related topics.
Google also announced that the main Webmaster central blog and other 13 localised blogs are moved to the new site.
All archived and new blog posts to be found here: https://developers.google.com/search/blog
Whoever has been following Google’s blog updates up until now, will not need to take any actions in case they want to keep receiving them. Of course, Google redirects all sets of RSS and email subscribers to the new blog URL.
As one would expect, Google’s search site centralisation comes with UX perks for all web professionals that feed their knowledge on the Google blog content:
- More discovery of related content (help documentation, localised blogs, event information, on one site)
- Easier to switch between languages (no longer have to find the localised blog URL)
- Better platform allows us to maintain the content, localise blog post more easily, and format posts consistently
From now on, the Googlebot Mascot will be joined by a sidekick which will accompany the bot in web crawling adventures.
When we first met this curious critter, we wondered, “Is it really a spider?” After some observation, we noticed this spider bot hybrid can jump great distances and sees best when surrounded by green light. We think Googlebot’s new best friend is a spider from the genus Phidippus, though it seems to also have bot-like characteristics.
Google
Googlebot can now crawl with HTTP/2 protocol beginning November 2020. Google Developer pages updated to reflect the change. Google updated their Googlebot Developers Support Page to reflect that Google is now able to try downloading pages via the latest HTTP/2 protocol.
12th Nov: the Googlebot starts crawling with HTTP/2 protocol
Google announces that the bot is now able to download pages through the latest HTTP/2 protocol.
The Googlebot Developers Support Page was updated on the 12th of November but the change was announced in September.
Generally, Googlebot crawls over HTTP/1.1. However, starting November 2020, Googlebot may crawl sites that may benefit from it over HTTP/2 if it’s supported by the site.
Google
Why HTTP/2 Network Protocol is good news?
It allows faster and more efficient transfer of data from the server to the browser (or Googlebot), reduces the web page delivery time from a browser to a server and, compresses HTTP header fields, and thus reduces overhead.
The HTTP/2 allows servers and browsers to download multiple resources with a single stream and from one connection instead of requesting multiple streams from multiple connections to download the same web page.
These HTTP/2 enhancements will ease off server congestion and save up server resources. This is highly beneficial for websites as oftentimes many search bots hit websites simultaneously, overloading web servers.
HTTP/2 is therefore contributing to the web page user experience as it keeps bot scrapers and hackers away letting Googlebot seamlessly crawl the website and helping to a smooth server function.
…starting November 2020, Googlebot may crawl sites that may benefit from it over HTTP/2 if it’s supported by the site.
Google
This may save computing resources (for example, CPU, RAM) for the site and Googlebot, but otherwise, it doesn’t affect the indexing or ranking of your site.
Ultimately, HTTP/2 protocol is good news for publishers and site owners as it helps Googlebot to crawl sites easier and reduce server load, making it also user friendly as sites become faster and more responsive.
To find out if your site is eligible for HTTP/2 please check here.
24th Nov: New Google search console crawl stats report
Google launches a new feature in Search Console, the Crawl Stats Report, that comes with a more granular reporting on how Google is crawling a website.
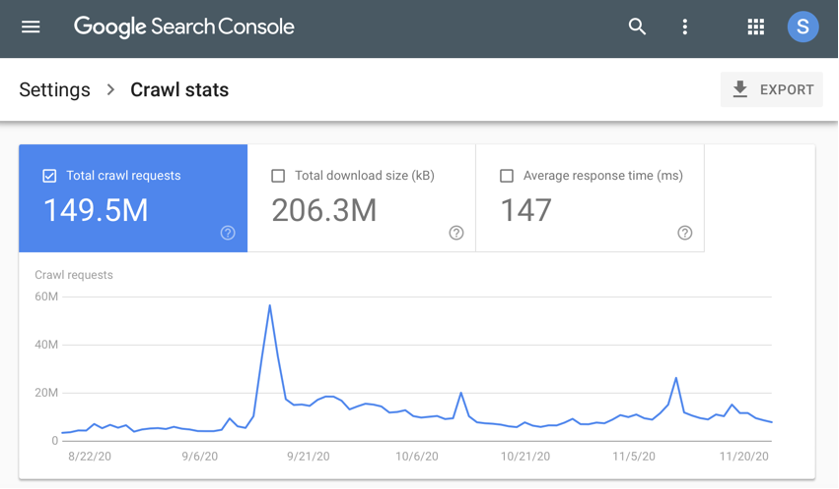
Google’s new Crawl Stat Report provides a 90-day track record of all files the Googlebot has downloaded, such as CSS, JavaScript, PDFs, and images.
The reason why this Search Console update is worthwhile lies in the fact that the Crawl Stats report capability offers help in tracking changes in crawling patterns.
Crawl pattern fluctuations can indicate that things are going right or wrong. Dropping crawl rates can mean issues with your server, issues with updates, or might to do with issues with content quality. Conversely, a crawl rate increase can be attributed to adding new quality content or even be a sign of misconfiguration that auto-generates duplicate or thin content pages.
Specifically, the new Crawl Stats Report come with the following new features:
- The total number of requests grouped by response code crawled file type, crawl purpose, and Googlebot type.
- Detailed information on host status
- URL examples to show where in your site requests occurred
- Comprehensive summary for properties with multiple hosts and support for domain properties
In summary, the new Crawl stats report will help you:
- See Google’s crawling history in the overtime charts
- See the file types and file sizes returned by your site
- See crawl requests details in the example lists
- Track your site’s availability issues in the host status view
All publishers should make Crawl Stats Report an indispensable part of their site monitoring process for search performance.
27th Nov: Google says anchor text is a ranking factor
In another Google SEO office-hours session and John Mueller shared insights on differences between linking to pages with long versus short anchor text.
Question:
“Do you treat anchor text that contains many words differently in comparison to anchor text that contains 2 words only?
I mean do you assign more value to those two words when you compare it to anchor text that has like 7 or 8 words?
For example – 2 words anchor text like “cheap shoes” and the 7 word anchor text is “you can buy cheap shoes here.”
Mueller said that anchor text length doesn’t necessarily impact rankings. What does impact rankings though seems to be more anchor text words that give Google more context about the page the anchor text is linked to.
Google needs context to better understand a page and rank it in the fairest and most effective way always based on its algorithm principles or else factors.
John Mueller responded:
I don’t think we do anything special to the length of words in the anchor text. But rather, we use this anchor text as a way to provide extra context for the individual pages.
John Mueller, Senior webmaster trends analyst at Google
Sometimes if you have a longer anchor text that gives us a little bit more information. Sometimes it’s kind of like just a collection of different keywords.
Sometimes if you have a longer anchor text that gives us a little bit more information. Sometimes it’s kind of like just a collection of different keywords.
So that’s kind of the way that I would look at it here. I wouldn’t say that shorter anchor text is better or shorter anchor text is worse, it’s just a different context.
Publishers should pay heed to this explanation and be strategic when deciding on the anchor text selection. It’s wise to use longer contextual anchor text for pages that matter the most so that Google understands better and, in turn, ranks it better.
What are the pages that usually matter the most?
- Most valuable pages of your site
- Pages that contain backlinks to your site
- Your Content contribution to other sites
- Content that contains mentions of your site/business/brand
In a nutshell, how our SEO agency London team interprets this, is that lengthy anchor texts don’t matter, but rather long anchor texts contextually related and relevant to the page they are linking to.
More insights from the team

